
 In CloudStack, secondary storage pools (image stores) house resources such as volumes, snapshots and templates. Over time these storage pools may have to be decommissioned or data moved from one storage pool to another, but CloudStack isn’t too evolved when it comes to managing secondary storage pools.
In CloudStack, secondary storage pools (image stores) house resources such as volumes, snapshots and templates. Over time these storage pools may have to be decommissioned or data moved from one storage pool to another, but CloudStack isn’t too evolved when it comes to managing secondary storage pools.
This feature improves CloudStack’s management of secondary storage by introducing the following functionality:
- Balanced / Complete migration of data objects among secondary storage pools
- Enable setting image stores to read-only (making further operations such as download of templates or storage of snapshots and volumes impossible)
- Algorithm to automatically balance image stores
- View download progress of templates across datastores using the ‘listTemplates’ API
Balanced / Complete migration of data objects among secondary storage pools
To enable admins to migrate data objects (ie. snapshots, templates (private) or volumes) between secondary storage pools an API has been exposed which supports two types of migration:
- Balanced migration – achieved by setting ‘migrationtype’ field of the API to “Balance”
- Complete migration –achieved by setting ‘migrationtype’ field of the API to “Complete”
If the migration type isn’t provided by the user, it will default to “Complete”.
Usage:
migrate secondarystoragedata srcpool=<src image store uuid> destpools=<array of destination image store uuids> migrationtype=<balance/complete>
Balanced migration:
The idea here is to evenly distribute data objects among the specified secondary storage pools. For example, if a new secondary storage is added and we want data to be placed in it from another image store, the “Balanced” migration policy would be most suitable.
As part of this policy there is a Global setting “image.store.imbalance.threshold” which helps in deciding when the stores in question have been balanced. This threshold (by default, set to 0.3) basically indicates the ideal mean standard deviation of the image stores. Therefore, if the mean standard deviation is above this set threshold, migration of the selected data object will proceed. However, if the mean standard deviation of the image stores (destination(s) and source) is less than or equal to the threshold, then the image stores have reached a balanced point and migration can stop. As part of the balancing algorithm, we also check the mean standard deviation of the system before and after the migration of a specific file and if the standard deviation increases then we omit the particular file and proceed further as its migration will not provide any benefit.
Complete migration:
Complete migration migrates a file if the destination image store has sufficient free capacity to accommodate the data object (used capacity is below 90% and is larger than the size of the file chosen). Also, during complete migration the source image store is set to “read-only”, in order to ensure that the store is no longer selected during any other operation involving storage of data in image stores.
- Source and destination image stores are valid (ie., are NFS based stores in the same datacenter)
- Validity of the migration type / policy passed
- Role of the secondary storage(s) is “Image”
- Destination image stores don’t include the source image store
- None of the destination image stores should be set to read-only
- There can be only one migration job running in the system at any given time
- If choice of migration is “Complete” then there should not be any files that are in Creating, Copying or Migrating states
Furthermore, care has been taken to ensure that snapshots belonging to a chain are migrated to the same image store. If snapshots are created during migration, then:
- If the migration policy is “complete” and the snapshot has no parent, then it will be migrated to the
- If the snapshot has a parent then the snapshot will be moved to the same image store as the parent
Another aspect of the migration feature is scaling of Secondary storage VMs (SSVMs) to prevent all migrate jobs being handled by one SSVM, which may hamper the performance of other activities that are scheduled to take place on it. The relevant global settings are:
- max.migrate.sessions. New. Indicates the number of concurrent file transfer operations that can take place on an SSVM (defaults to 2)
- ssvm.count. New. maximum number of additional SSVMs that can be spawned up to handle the load. (defaults to 5). However, if the number of hosts in the datacenter is less than the max count set, then the number of hosts takes precedence
- vm.auto.reserve.capacity. Existing. Should be set to true (default) if we want scaling of SSVMs to when the load increases
Additional SSVMs will be created when half of the total number of jobs have been running for more than the duration defined by the global setting max.data.migration.wait.time (default 15 minutes). Therefore, ifmigrate job has been running for more than 15 mins then a new SSVM is spawned and jobs can be scheduled on it.
These additional SSVMs will be automatically destroyed when:
- The migration job has reached completion
- The total number of commands in the pipeline (as determined by the cloud.cmd_exec_log table) is below the defined threshold
- There are no jobs running on the SSVM in question
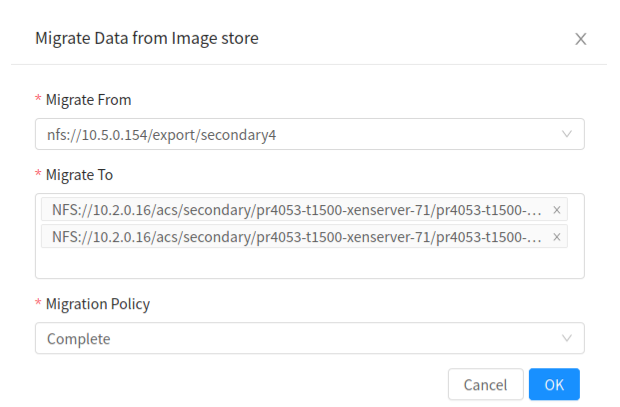
UI Support:
As well as using the API (cloudmonkey / cmk), support has been added in the new Primate UI.
Navigate to: Infrastructure → Secondary Storages At the top right corner, click on migrate button:
Enable setting image stores to read-only
A secondary storage pool may need to be set to read-only mode, to prevent downloading objects onto it. This could prove useful when decommissioning a storage pool. An API has been defined to enable setting a Secondary storage to read only:
update imagestore id=<image_store_id> readonly=<true/false>
It is possible to filter out image stores based on read-only / read-write permissions using the API ‘listImagestores’.
Algorithm to automatically balance image stores
Currently the default behaviour of CloudStack is to choose an image store with the highest free capacity. There is a new global setting: “image.store.allocation.algorithm”, which by default is set to “firstfitleastconsumed”, meaning that it returns the image stores in decreasing order of their free capacity. Another allocation option is ‘random’, which returns image stores in a random order.
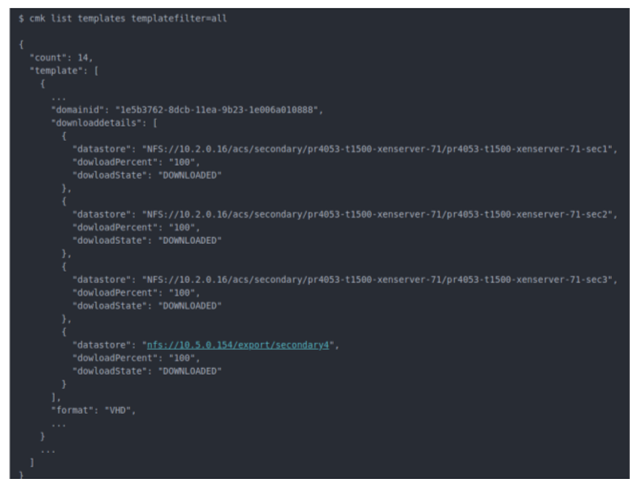
View download progress of templates across datastores using the ‘listTemplates’ API
The “listTemplates” API has been extended to support viewing download details: progress, download status, and image store. For example:
This feature will be available as of Apache CloudStack 4.15, which will be an LTS release.
Pearl is a quality and technology driven software engineer, with 5 years’ experience with relevant expertise in providing solutions to the telecom and software industry. Pearl has an excellent grasp of the evolving technologies in the changing telecom space. She is a go-getter, with a flair for learning new technologies. Pearl is based in Bangalore, India. Self-learning and self-motivation are the mantras that she follows to keep herself abreast with new things in her field of work.






