
Historically, all Primary Storage Pools inside CloudStack were Cluster-wide. Each Pool was “dedicated” to one cluster only – or in other words, only hosts in one cluster could access/use that Primary Storage Pool. This was an inheritance of the traditional storage implementations in various hypervisors – i.e. a Datastore in vSphere mounted on hosts in one cluster, or a Storage Repository mounted on hosts in a single XenServer cluster, etc.
Over the years, different storage solutions appeared and support for those has changed in the hypervisor world. For some of them, it made sense to ensure that multiple clusters can share the same storage. A typical example is if you are using Ceph, SolidFire or some other software-defined storage solutions (which are frequently also distributed in their nature). For this purpose, CloudStack has implemented the concept of a Zone-wide Primary Storage Pool – meaning that all hosts in all clusters in a given Zone will be able to access Pool. It’s worth noting that Zone-wide Pools are only supported with vSphere and KVM as hypervisors, while XenServer/XCP-ng only supports Cluster-wide pools.
Sometimes, you could start your deployment small, have one cluster and a Cluster-wide storage pool for it. But over time, as your infra grows and evolves, it might happen that you would want your existing Primary Storage Pools to be Zone-wide instead of currently Cluster-wide. This is possible with some changes to the CloudStack database and also on the hypervisor level. In the rest of this article, we’ll explain how to do this with the most common storage types, such as NFS and Ceph – for the supported hypervisors (vSphere and KVM).
2024 Update
As of version 4.19.1. CloudStack has added a UI/API feature to convert a cluster-wide storage pool to a zone-wide and vice versa, which fully automates the whole process. We recommend you use this feature instead of manually doing the changes, as it lowers the chance of making wrong changes in the database. The feature is supported/tested for KVM with CEPH and NFS, and for VMware with NFS (it might also be possible to convert other types of storage pools with some additional manual intervention on the hypervisor side). You can read more about the steps here. However, if you decide to do it manually, the rest of the article (below) still applies.
KVM with NFS/Ceph
If you are using KVM with NFS or Ceph, all the changes can be done without any downtime.
You should log in to the database and identify the Primary Storage Pool which you want to convert from Cluster-wide to Zone-wide, e.g.:

In the given example, we see a pool with ID 3, which is Cluster-wide, and belongs to Cluster2 (in Pod1).
You will want to update the DB as follows:
UPDATE cloud.storage_pool SET pod_id=NULL, cluster_id=NULL, scope=’ZONE’ WHERE id=3;
Here – you’ve “informed” CloudStack that this Pool now has “ZONE” scope, and have set the pod_id and cluster_id fields to NULL (which is expected for Zone-wide Primary Storage Pools).
NOTE: in some cases, the “hypervisor” column of the “storage_pool” table might also need to be updated accordingly – it defines for which kind of hypervisor the storage pool is available. Since we are talking KVM here, the value of the “hypervisor” column should always be “KVM”, irrelevant if the storage pool is zone-wide or cluster-wide.
Repeating the previous query should reflect the changes made:

Additionally, we should also update the “op_host_capacity” table by setting the values of the “pod_id” and “cluster_id” to null, for the specific storage pool
UPDATE op_host_capacity SET pod_id=NULL,cluster_id=NULL WHERE host_id=3;
Please note the above field “host_id” at the end of the query – this is actually the ID of the storage pool from the storage_pool table (which is “3” in our example)
After the database has been properly updated, we will need to ensure that CloudStack Agent will reconnect to the Management server. This can be done in 2 ways, depending on how you want to do it, and depending on the maintenance window:
- Restart the cloudstack-agent on each KVM host that needs to mount this “new” pool.
- Restart all cloudstack-management servers, one by one.
In both cases, CloudStack Agent will lose connection to the Management server, and after reconnecting, it will obtain a list of Primary Storage Pools that it should have, and set/mount those which are missing. Monitoring the agent logs on the “new” KVM hosts (/var/log/cloudstack/agent/agent.log) – will show you the pool being detected as missing and being added to the KVM hosts. Lines below are from our example case:
2023-02-09 13:33:00,619 INFO [kvm.storage.LibvirtStorageAdaptor] (agentRequest-Handler-3:null) (logid:b93f986d) Attempting to create storage pool 22fa5e9a-9246-3059-aa91-e7d8002a66ed (NetworkFilesystem) in libvirt
2023-02-09 13:33:00,621 WARN [kvm.storage.LibvirtStorageAdaptor] (agentRequest-Handler-3:null) (logid:b93f986d) Storage pool 22fa5e9a-9246-3059-aa91-e7d8002a66ed was not found running in libvirt. Need to create it.
Needless to say, you need to ensure network connectivity between the “new” hosts and the storage pool, in the first place.
If you now list storage pools in KVM, you should be able to see the pool added to those KVM hosts which didn’t have it before (KVM hosts in other clusters in your Zone):
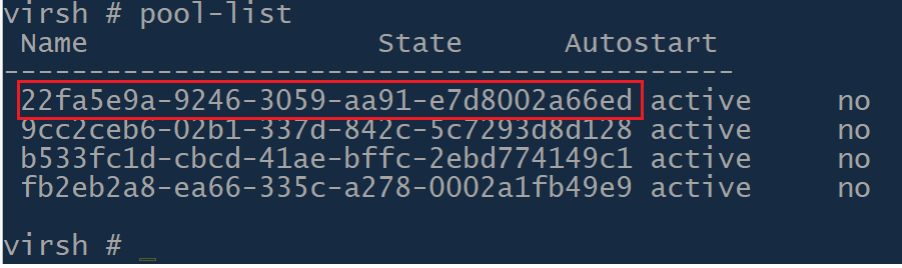
And that is pretty much it. This is applicable for both NFS and Ceph primary storage pools, but with some modifications and preparations of the KVM/Linux systems (which are standard for those storage solutions), you would be able to also convert i.e. SolidFire storage from Cluster-wide to Zone-wide, and probably many other Shared storage solutions. Think of this as adding additional hosts in the existing KVM cluster and having to do needed Linux preparations (i.e. installing iSCSI utils) so that the Pool can be mounted on those additional hosts. Though in our case, CloudStack is not automatically adding pools to those hosts, we are triggering that manually instead.
In case you want to go backwards, to convert a Primary Storage Pool from Zone-wide to Cluster-wide, the procedure would be similar, albeit in reverse steps. High-level guidance is listed below:
- disable the selected Primary Storage Pool in CloudStack (Disable, NOT put into Maintenance mode) – this will ensure no new volumes can be created on this Pool.
- migrate all those VMs, that have volumes on the affected pool, to a destination cluster’s hosts to which you want to scope the pool – so that no VM is running on hosts outside the cluster to which you are scoping the pool.
- define “pod_id” and “cluster_id” fields in the “storage_pool” table with proper Pod ID and Cluster ID, and also change the “scope” field to “CLUSTER”, while ensuring the correct value in the “hypervisor” column)
- define “pod_id” and “cluster_id” fields in the “op_host_capacity” table with proper Pod ID and Cluster ID.
- Restart all cloudstack-management servers, one by one
- Enable back the Primary Storage Pool in the CloudStack
- Once everything is in place, you can “destroy” the pool definition in KVM with “virsh pool-destroy <POOL_UUID>”
VMware with NFS
In case you are running VMware with NFS (or perhaps CloudStack-managed iSCSI, which is not usual to do in production probably due to lack of multipath possibilities), you can also achieve the needed changes with no downtime.
The procedure is almost identical to the one for KVM. We will have to do the same kind of changes in the CloudStack database, and then restart all cloudstack-management servers one by one – for details please see the DB changes in the KVM part of this article.
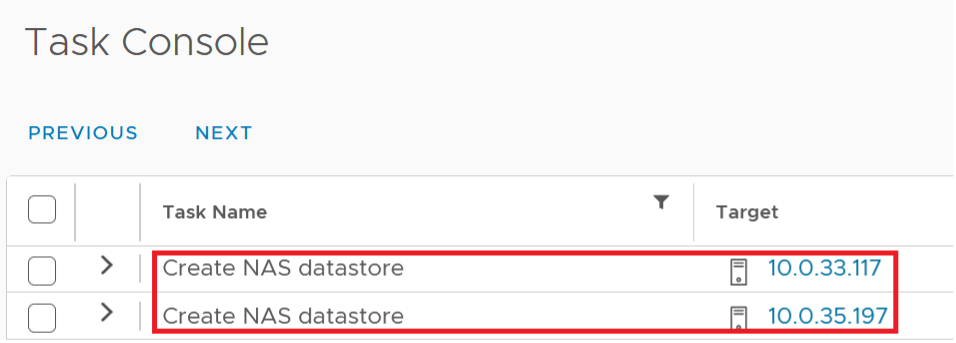
Once the DB changes are done, and the management servers are restarted – you will be able to see in logs (as well as in vCenter) CloudStack mounting the storage pools (Datastores) to the “new” clusters’ ESXi hosts:
2023-02-10 13:04:10,001 DEBUG [c.c.s.StorageManagerImpl] (AgentTaskPool-2:ctx-91367d3f) (logid:a5243f1c) Adding pool Prim2-CL2 to host 4
2023-02-10 13:04:10,017 DEBUG [c.c.s.StorageManagerImpl] (AgentTaskPool-1:ctx-2d133fbb) (logid:7b509eb1) Adding pool Prim2-CL2 to host 3
2023-02-10 13:04:10,209 DEBUG [c.c.s.StorageManagerImpl] (AgentTaskPool-3:ctx-5c5cdfe2) (logid:d8187e98) Adding pool Prim2-CL2 to host 7
2023-02-10 13:04:10,641 DEBUG [c.c.s.StorageManagerImpl] (AgentTaskPool-4:ctx-49530de0) (logid:7449b432) Adding pool Prim2-CL2 to host 8
In our example above, the storage pool (an NFS Datastore) was already mounted/present on host 7 and host 8 – but is now also being added to host 3 and host 4. You should also see the corresponding actions in the vCenter:
For reverting back from Zone-wide to Cluster-wide Primary Storage Pool the steps are pretty much identical as for the KVM. Please, see the KVM part of this article.
The difference would be to pay attention to disabling VMware DRS in case it’s active in your environment before migrating VMs to the destination cluster’s ESXi hosts (and later enabling it, once everything is done).
And that’s it – pretty simple – but as usual, make sure to test everything in a test environment to avoid any surprises!
About the author
Andrija Panic is a Cloud Architect at ShapeBlue, the Cloud Specialists, and is a committer and PMC member of Apache CloudStack. Andrija spends most of his time designing and implementing IaaS solutions based on Apache CloudStack.
Andrija Panic is a Cloud Architect at ShapeBlue and a PMC member of Apache CloudStack. With almost 20 years in the IT industry and over 12 years of intimate work with CloudStack, Andrija has helped some of the largest, worldwide organizations build their clouds, migrate from commercial forks of CloudStack, and has provided consulting and support to a range of public, private, and government cloud providers across the US, EMEA, and Japan. Away from work, he enjoys spending time with his daughters, riding his bike, and tries to avoid adrenaline-filled activities.
You can learn more about Andrija and his background by reading his Meet The Team blog.






